Predictive Analysis of Bank Customer Churn in Python: Enhancing Retention Strategies through Machine Learning
1. Figure
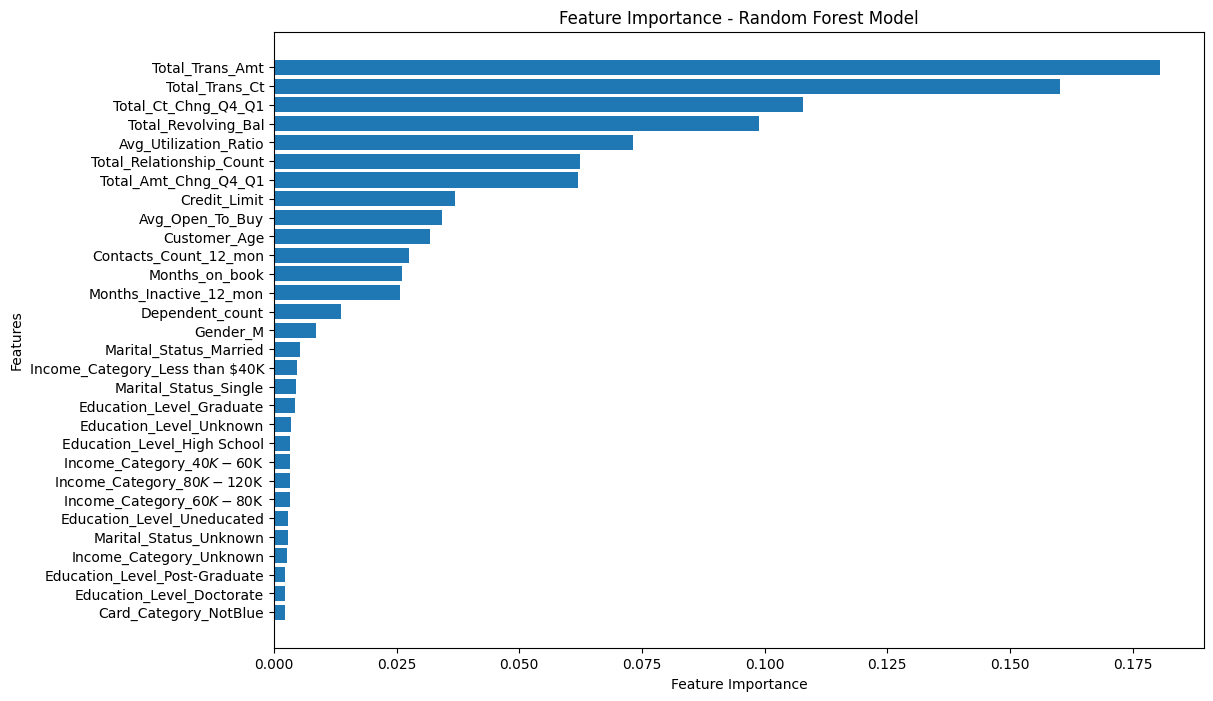
[Fig. Random Forest Features by Importance]
2. Figure
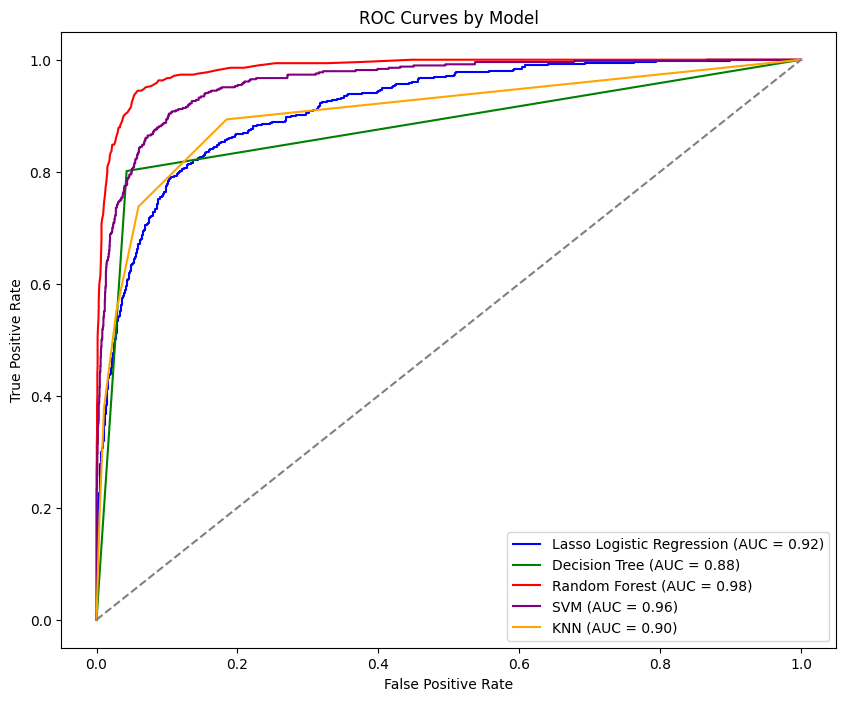
[Fig. ROC Curves by Each Model]
2. Goal
The primary goal of this project was to predict customer churn using various machine learning models. By accurately identifying customers likely to churn, the analysis aimed to provide insights that could inform customer retention strategies and improve decision-making processes in customer relationship management.
3. Methodology & Summary
Methodology: The project involved an exploratory data analysis to understand customer demographics, transaction behaviors, and financial habits. This was followed by preprocessing the data, including feature scaling and encoding. Various machine learning models such as random forest, support vector machine (SVM), decision tree, k-nearest neighbor (kNN), and LASSO logistic regression were then trained and evaluated. The model’s performance assessment was conducted by evaluating it against various criteria, including accuracy, precision, recall, and the area under the curve (AUC).
Summary: The Random Forest model emerged as the top performer with an accuracy of 95.39% and an AUC score of 0.98. Key variables influencing churn, consistent across models, included Total Transaction Amount (
Total_Trans_Amt), Total Transaction Count (Total_Trans_Ct), and others. The analysis provided valuable insights into factors driving customer churn, highlighting the potential for targeted retention strategies and data-driven decision-making in banking services.